Research Portfolio

HCI · Accessibility · Input Devices
Wheeler
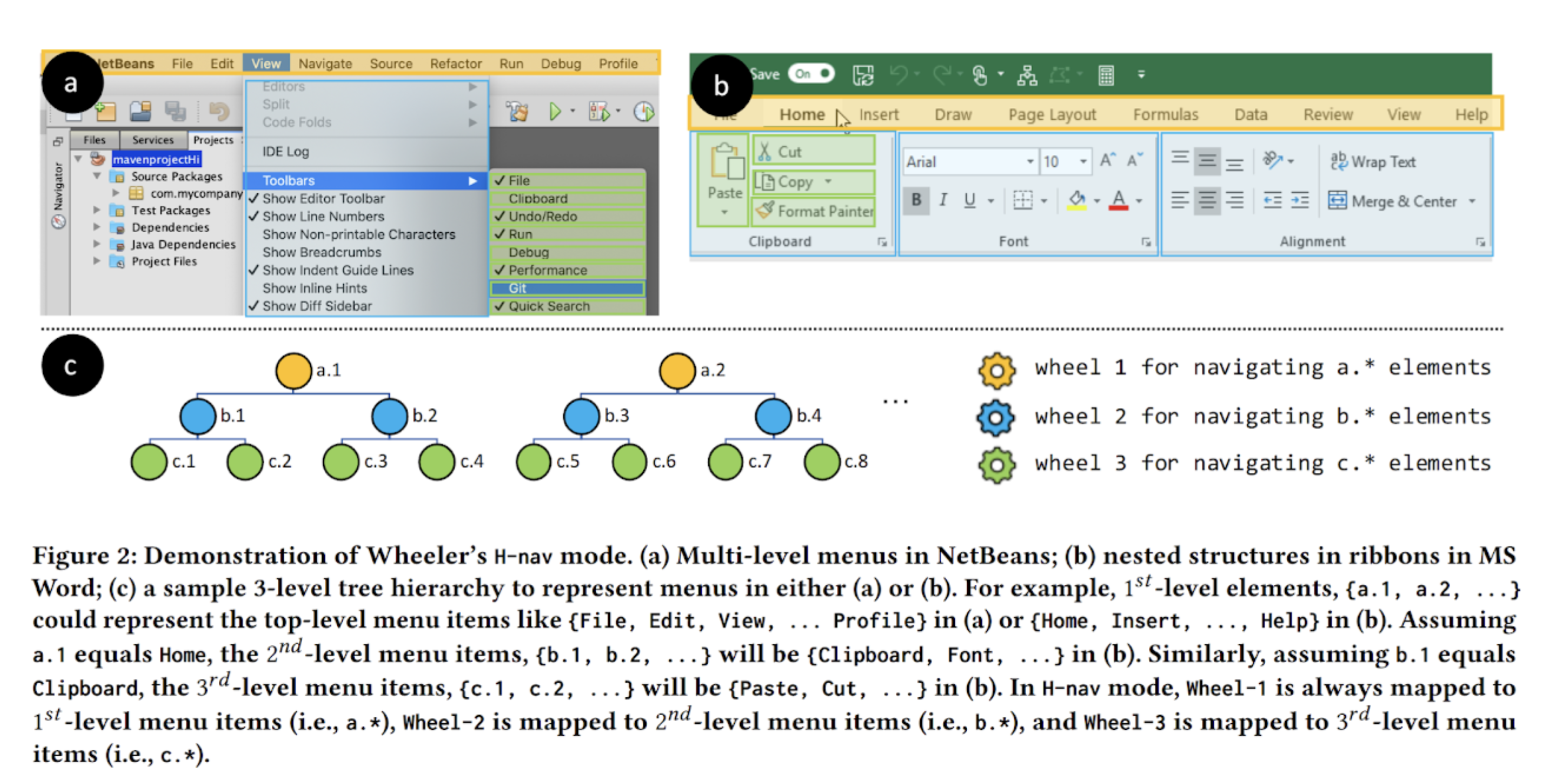
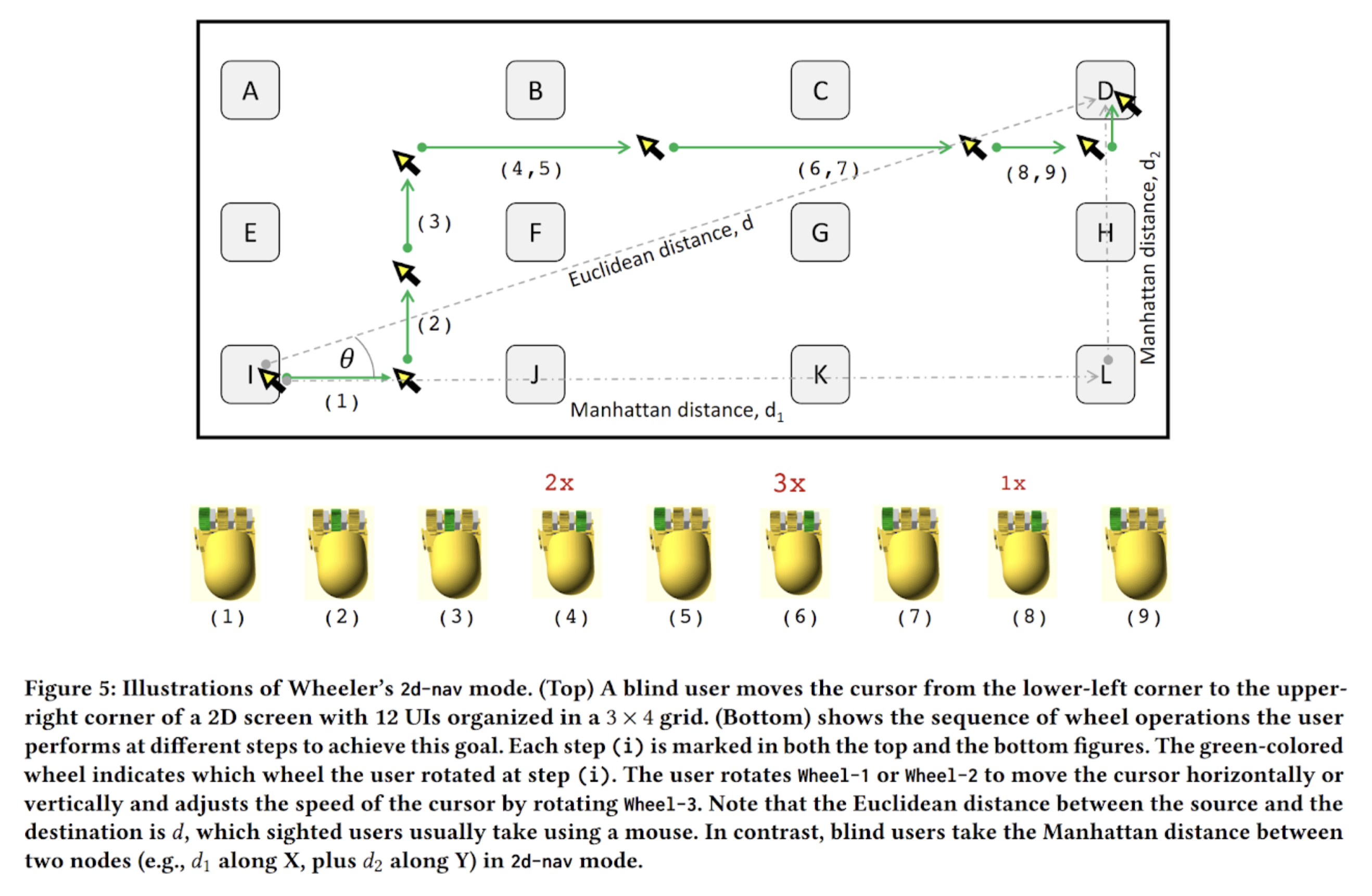
A mouse-shaped input device with three independently rotatable wheels for faster GUI navigation.

Computer Vision · VLMs · Evaluation
IKIWISI
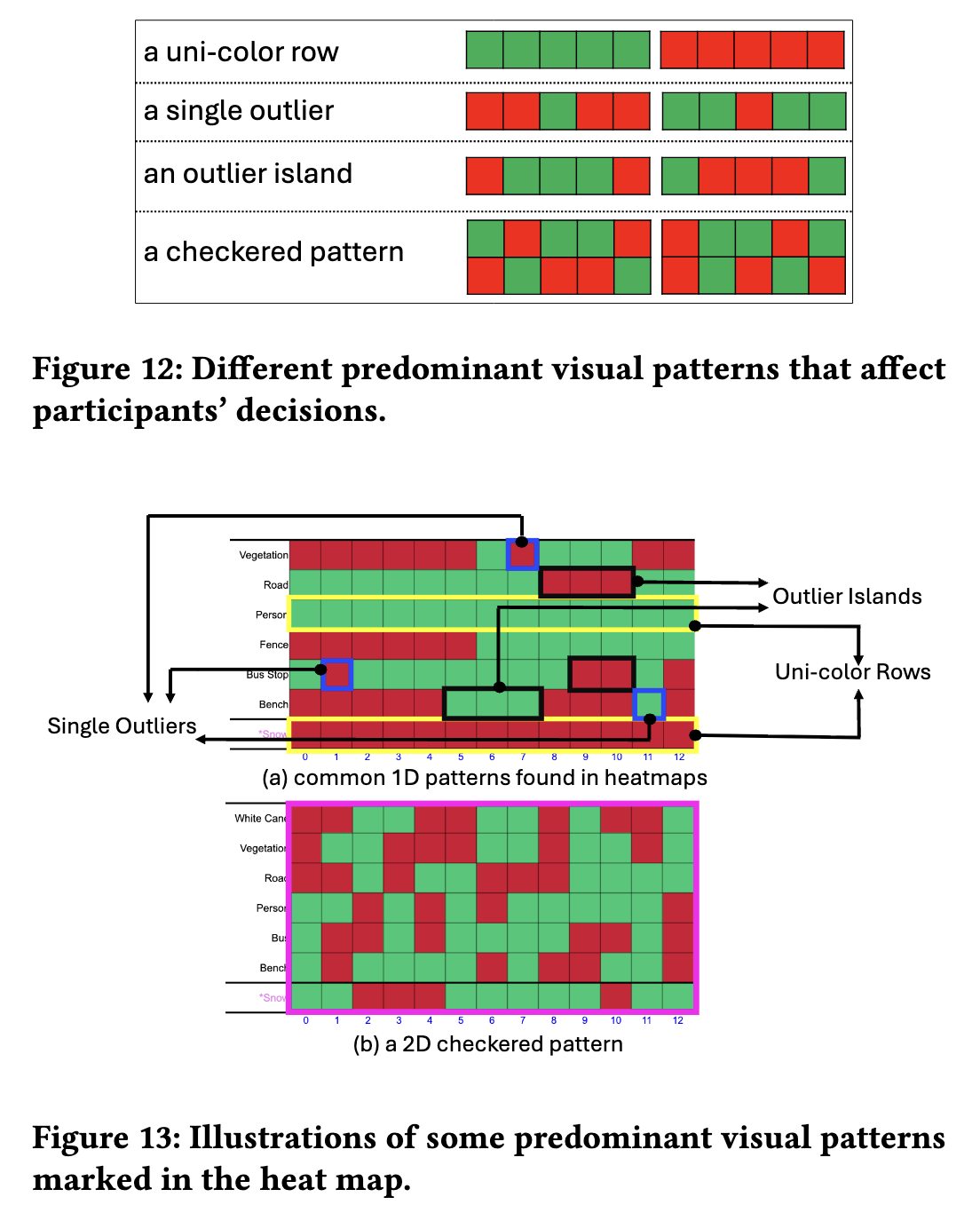
A heatmap-based tool for evaluating VLM reliability without ground truth across video frames.

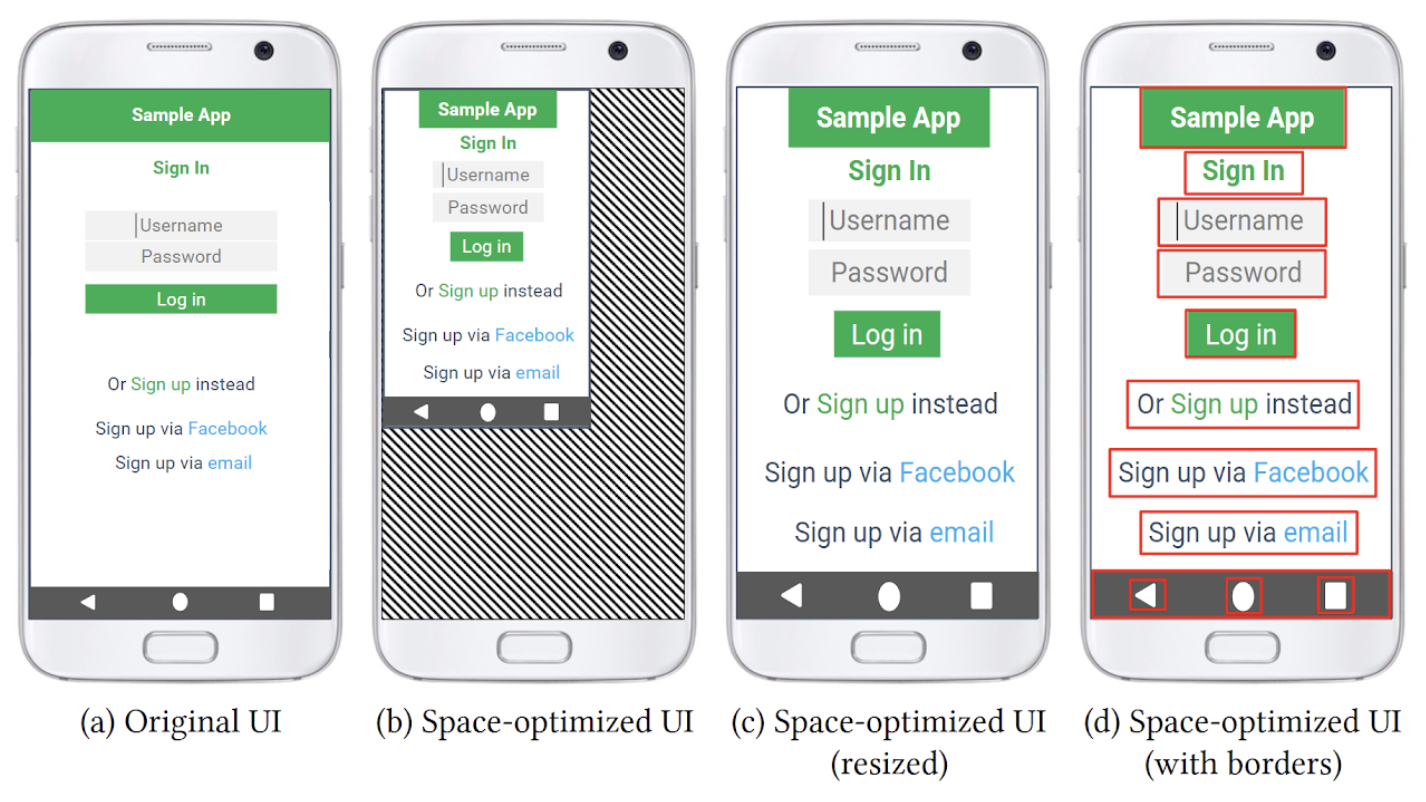
HCI · Accessibility · Mobile
SpaceXMag
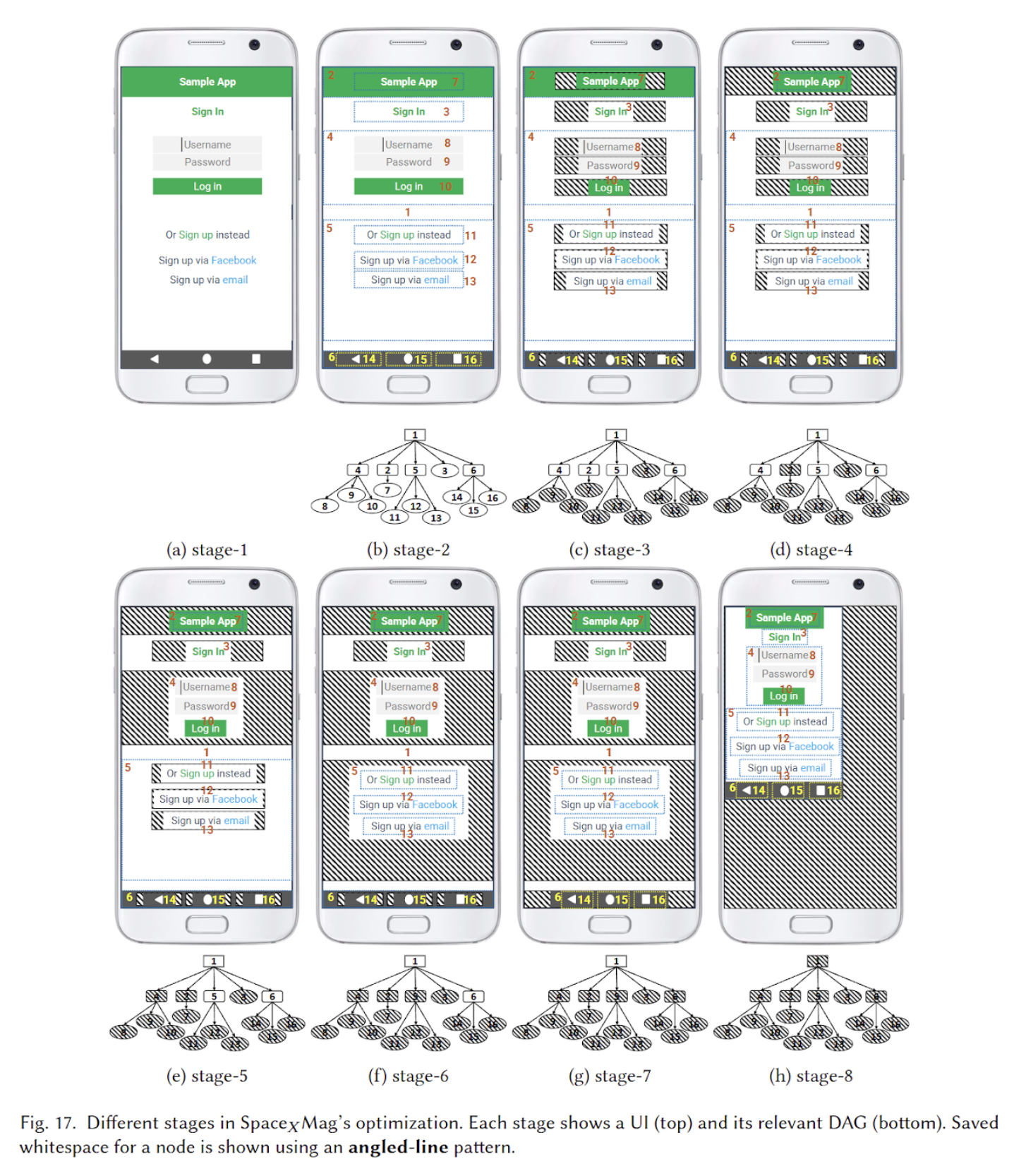
An automatic space compactor for low-vision smartphone users, reducing whitespace under magnification.
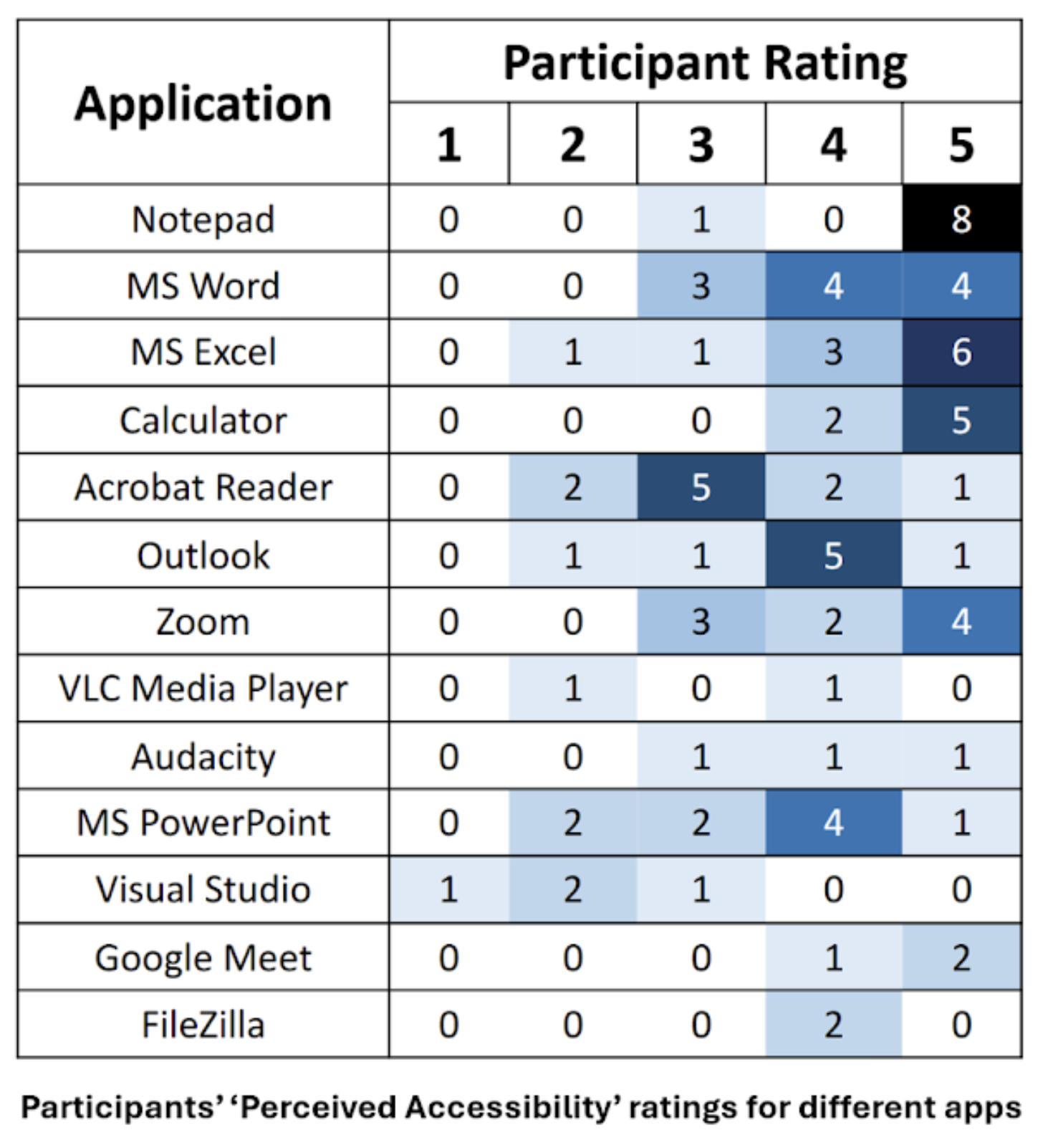
HCI · Accessibility · Desktop
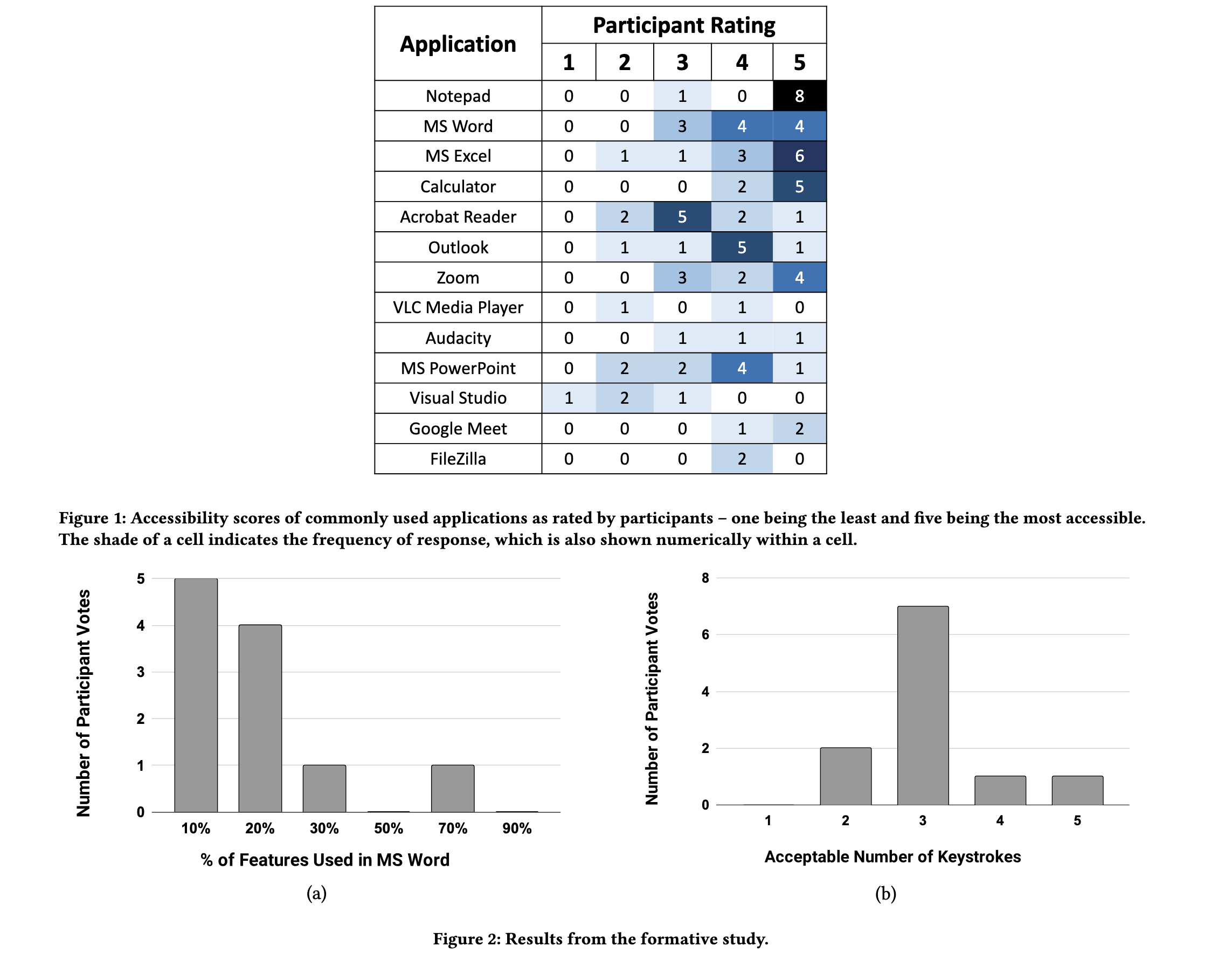
Accessibility Metrics
A probabilistic framework for estimating perceived accessibility of desktop apps in non-visual interaction.
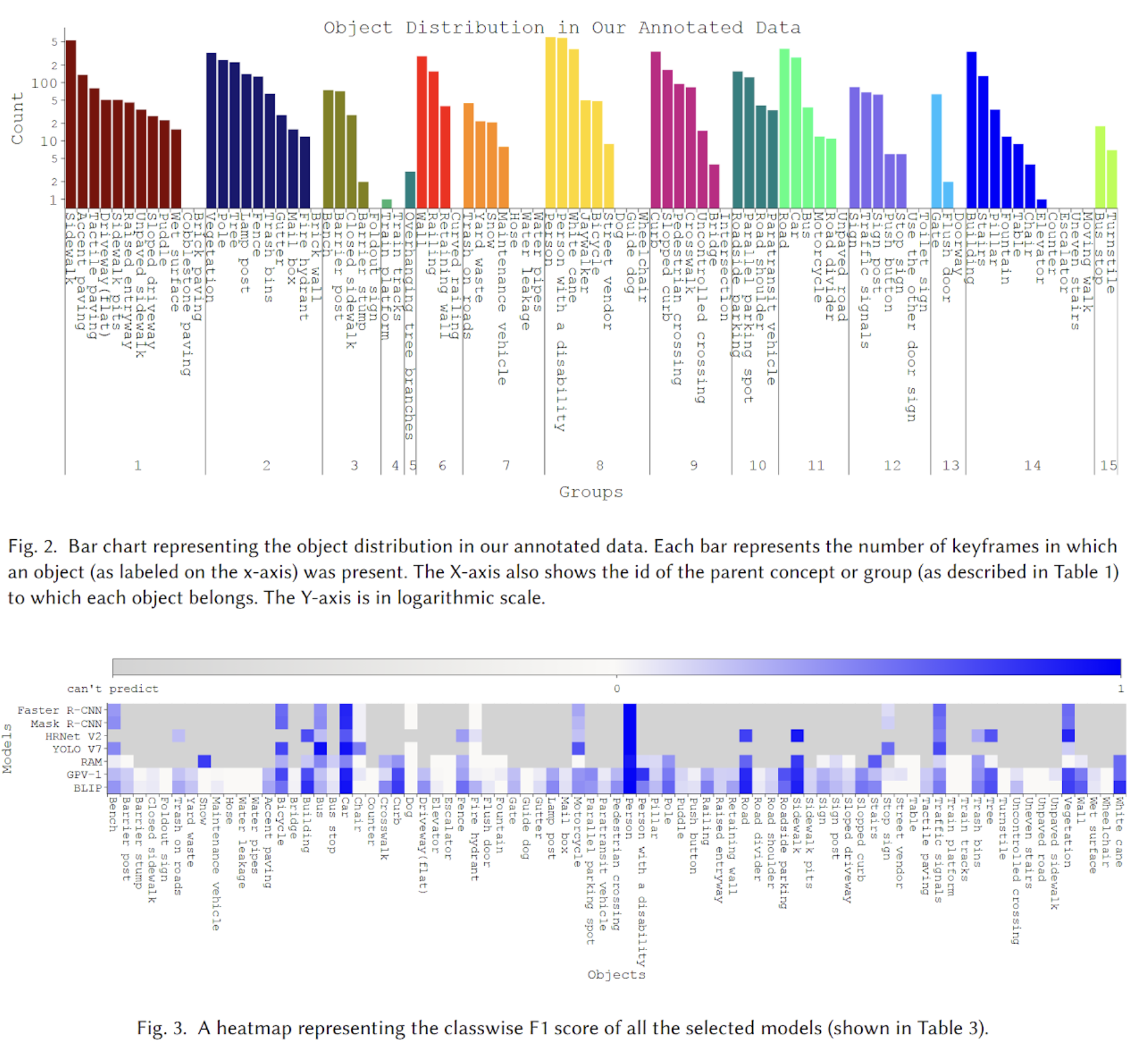
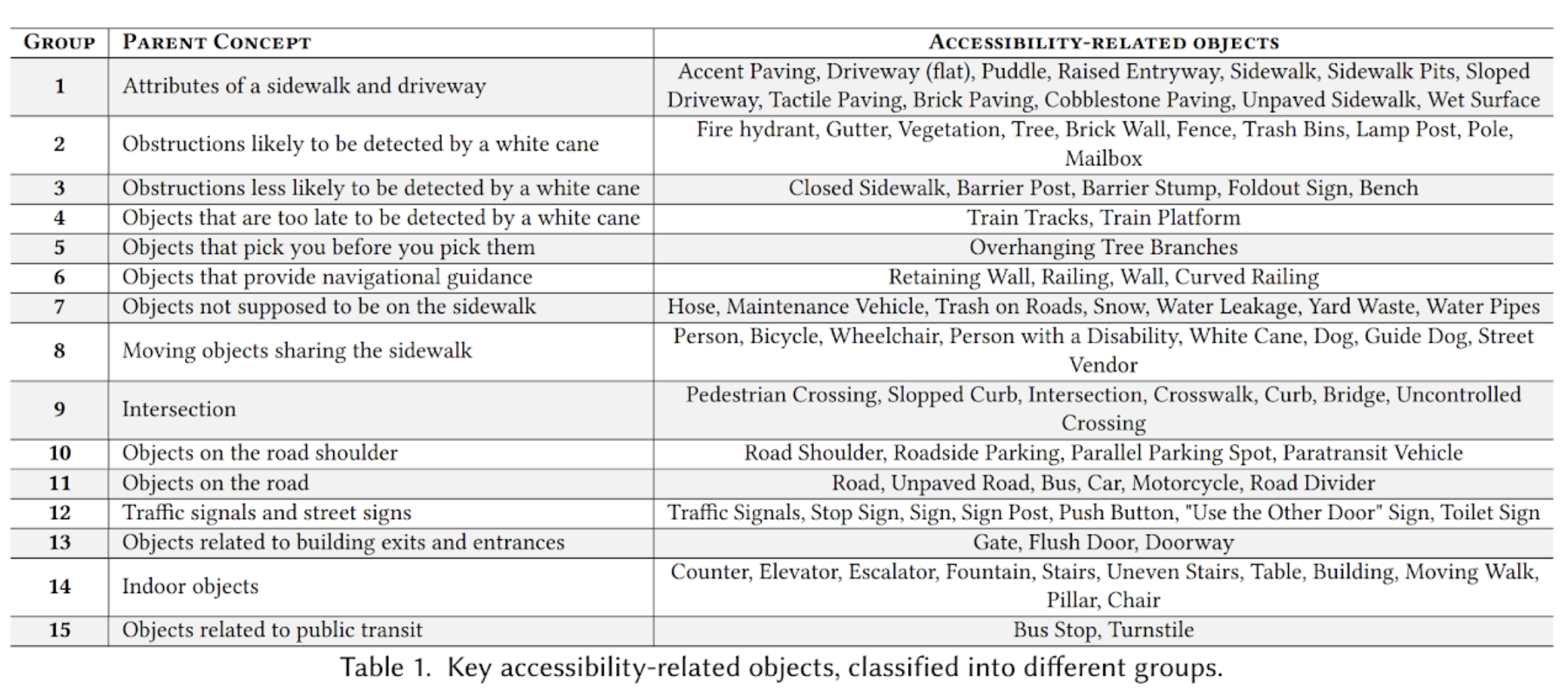
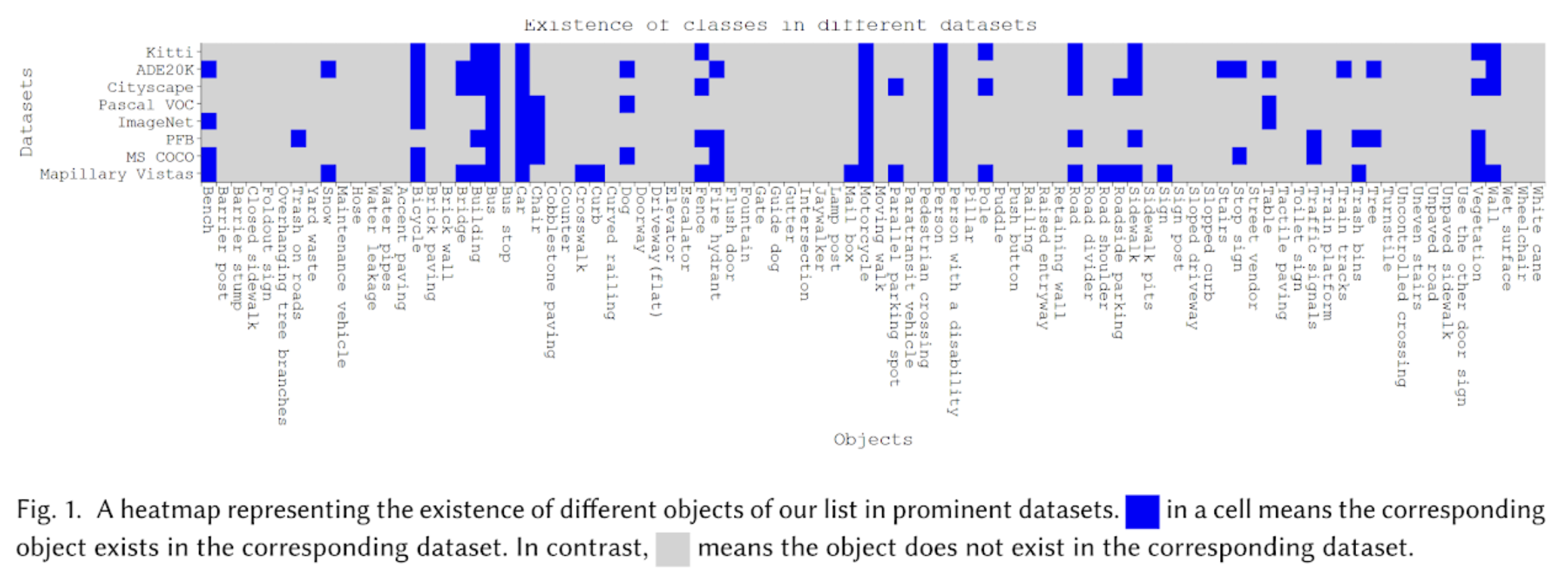
Accessibility · Computer Vision
BLV Road Nav Objects
A taxonomy and benchmark of 90 objects crucial for blind and low-vision individuals' navigation.

LLMs · Education · Agentic AI
TeachPilot
A teacher-guided classroom LLM assistant that adapts per assignment with instructor-defined guardrails.

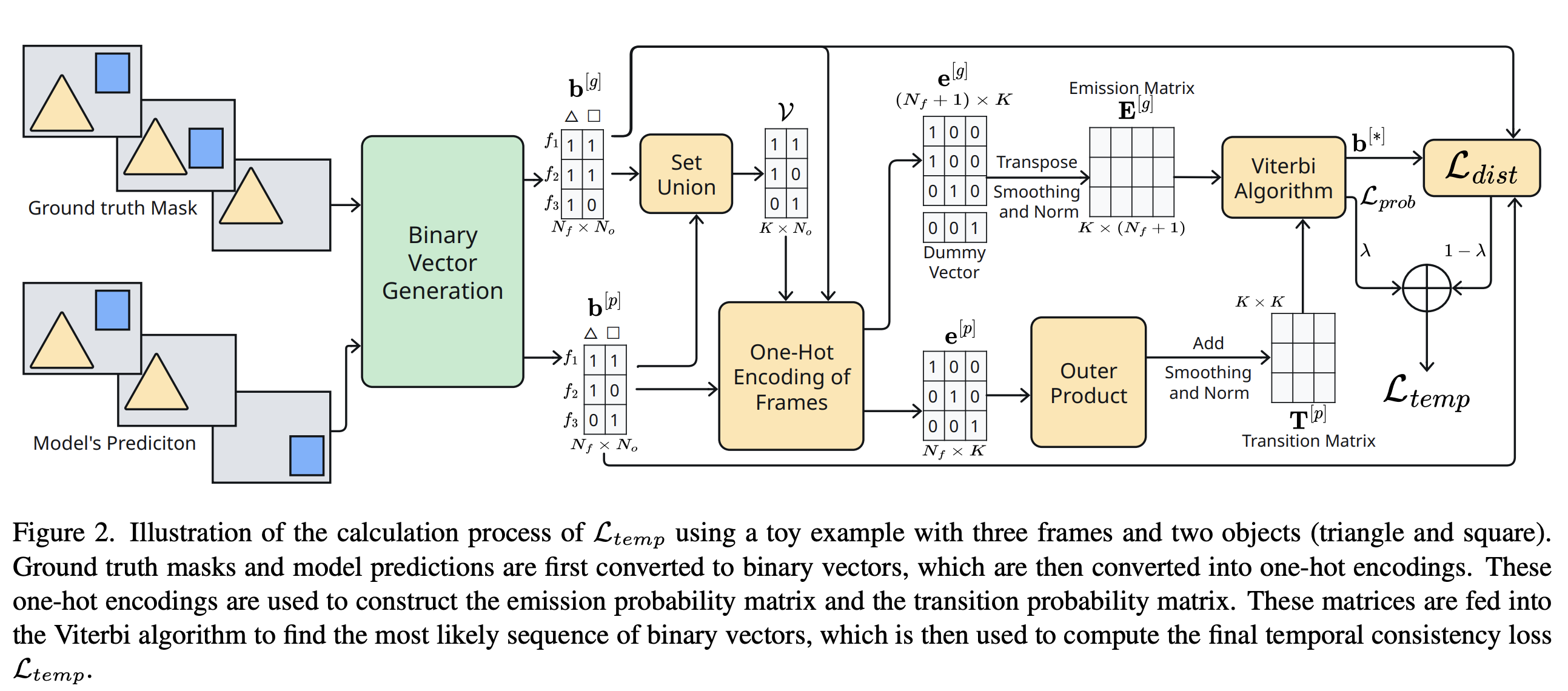
Computer Vision · Video Segmentation
Temporal VOS Loss
A model-agnostic temporal consistency loss improving VOS robustness under occlusion and reappearance.
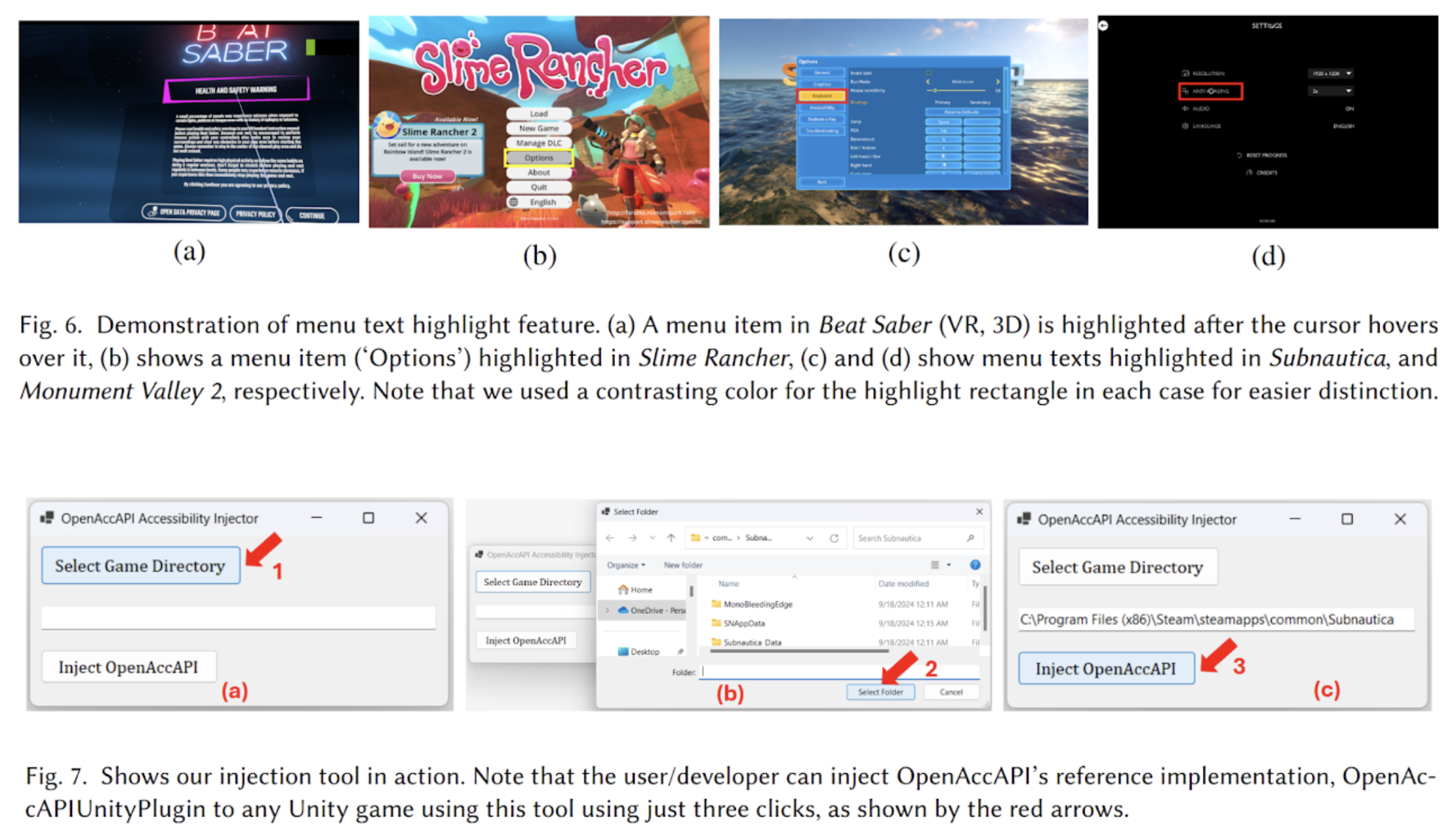
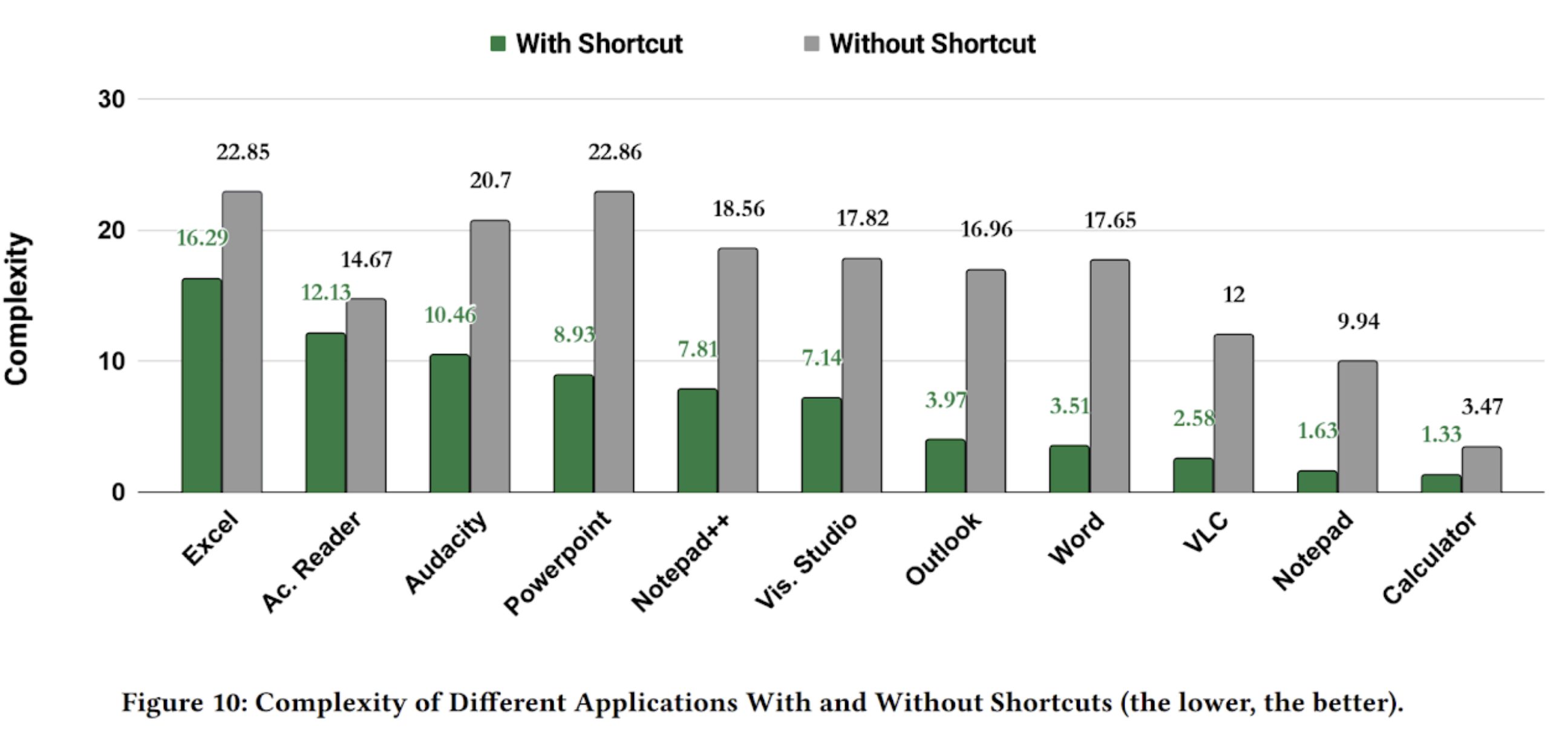
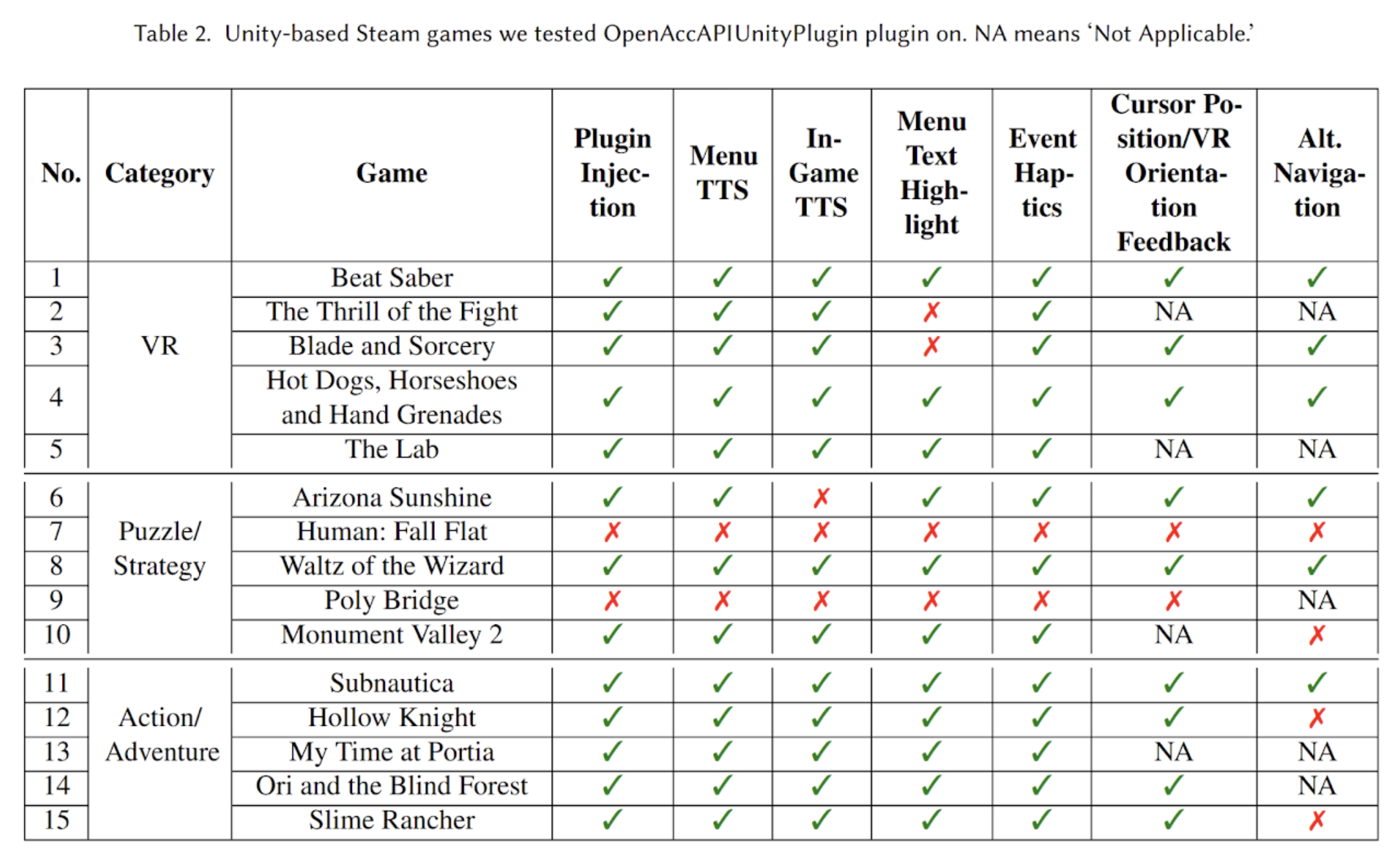
HCI · Accessibility · VR/XR
OpenAccAPI
An open-source accessibility API for 3D and VR apps enabling numerous accessibility features in existing Unity games.

Computer Vision · 3D Scenes · LLMs
Object Trajectory Narratives (OTN)
A structured motion grammar replacing pixel inputs with engine telemetry for 3D scene reasoning.

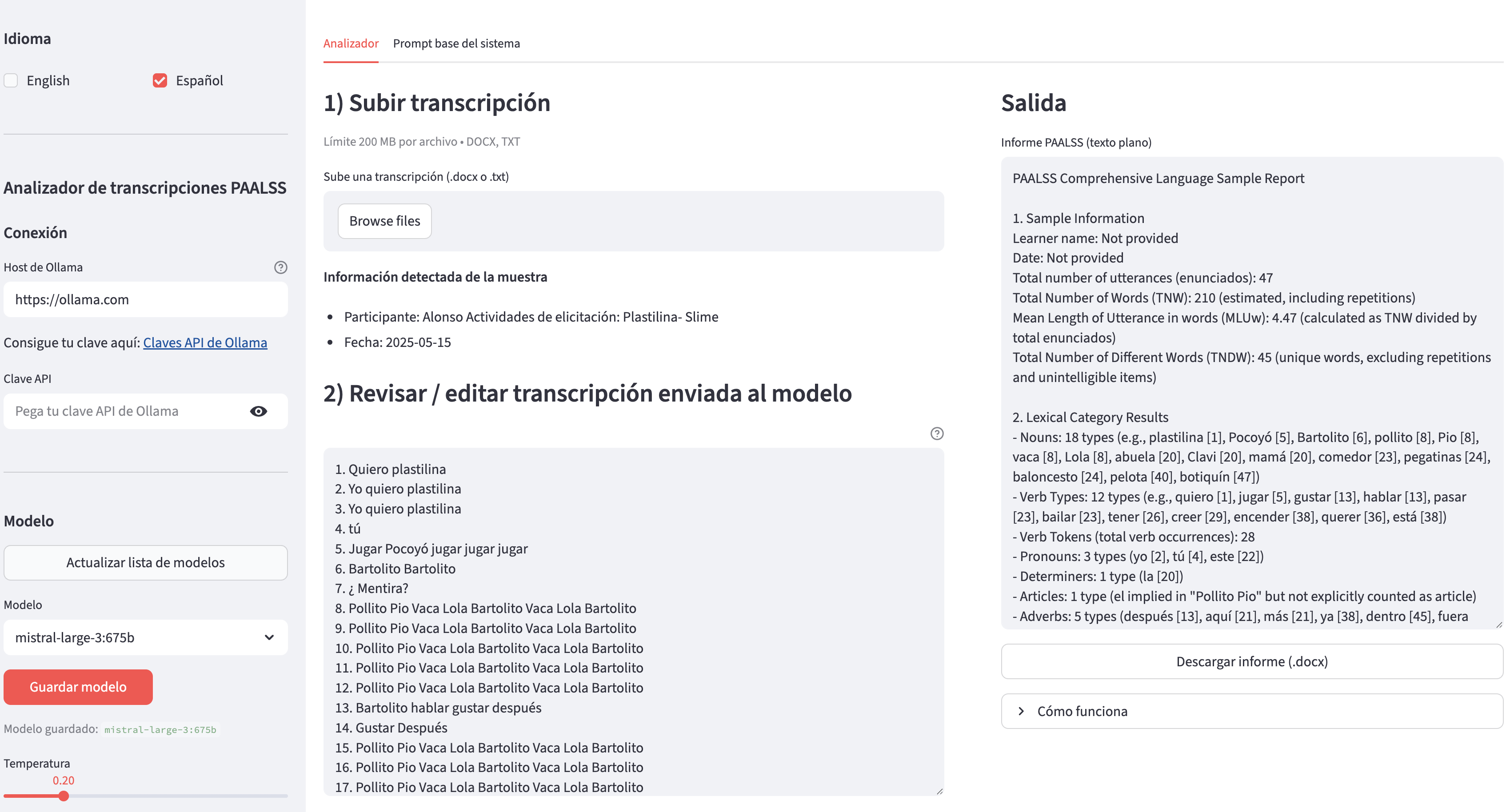
LLMs · Clinical Drafting · Accessibility
PAALSS Analyzer
An LLM-based analyzer for generating PAALSS-style reports from Spanish aided AAC transcripts via Ollama.

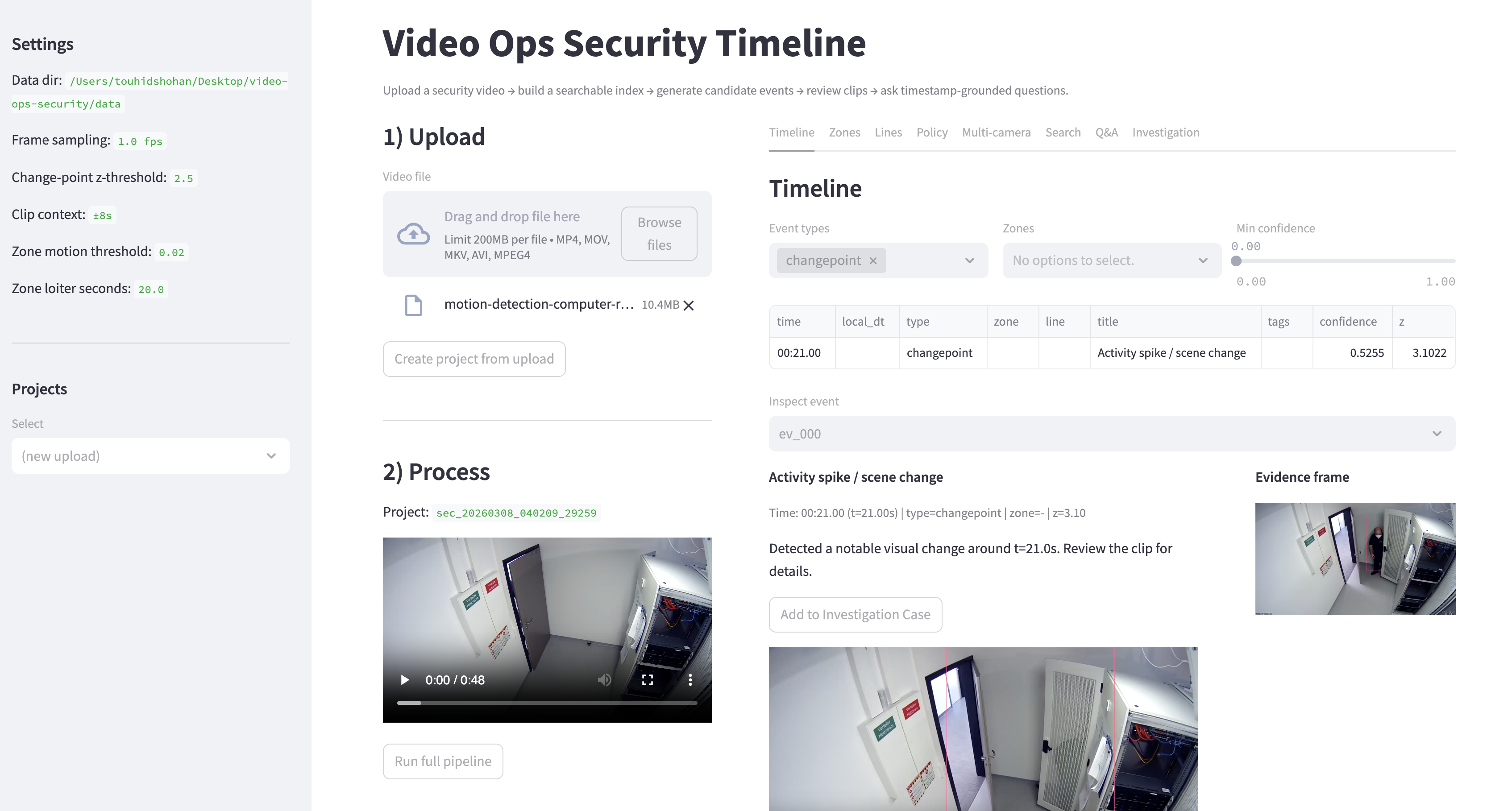
Computer Vision · Video Analysis · Systems
ForenSight
A local-first video investigation pipeline for grounded text-to-timestamp retrieval and event detection.
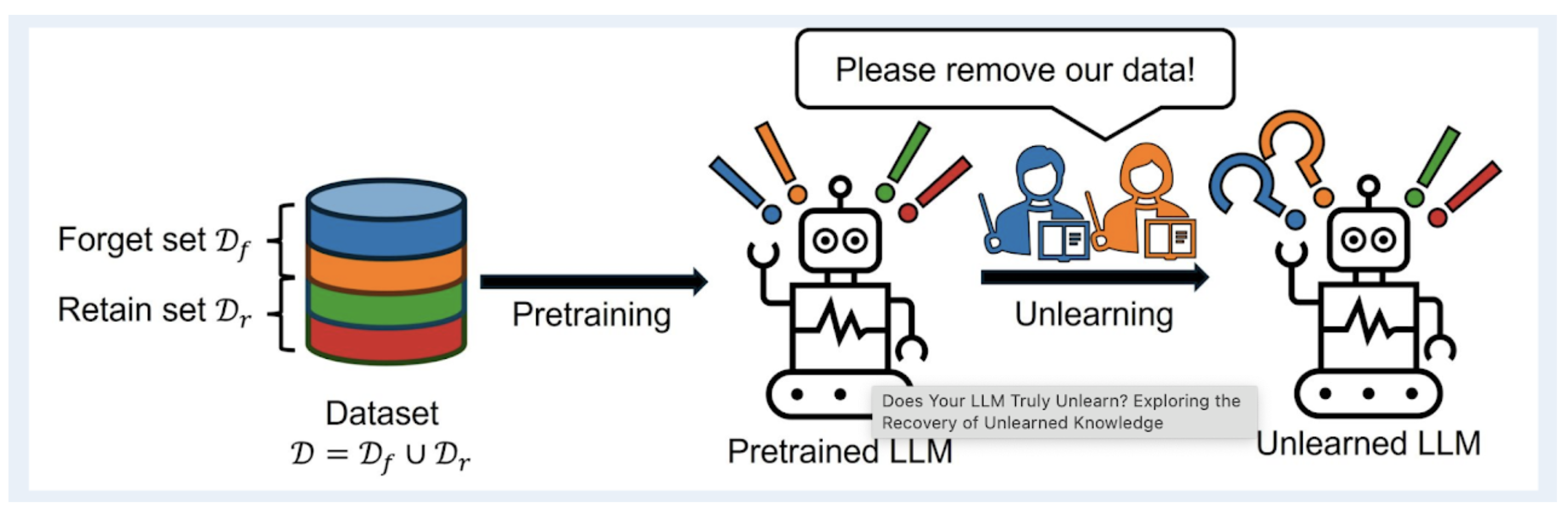
LLMs · PEFT · Machine Unlearning
LLM Unlearning with Synthetic Data
A parameter-efficient unlearning pipeline using LoRA to remove targeted behaviors from LLMs.